Multi-passage Model Update
Completed BiDAF
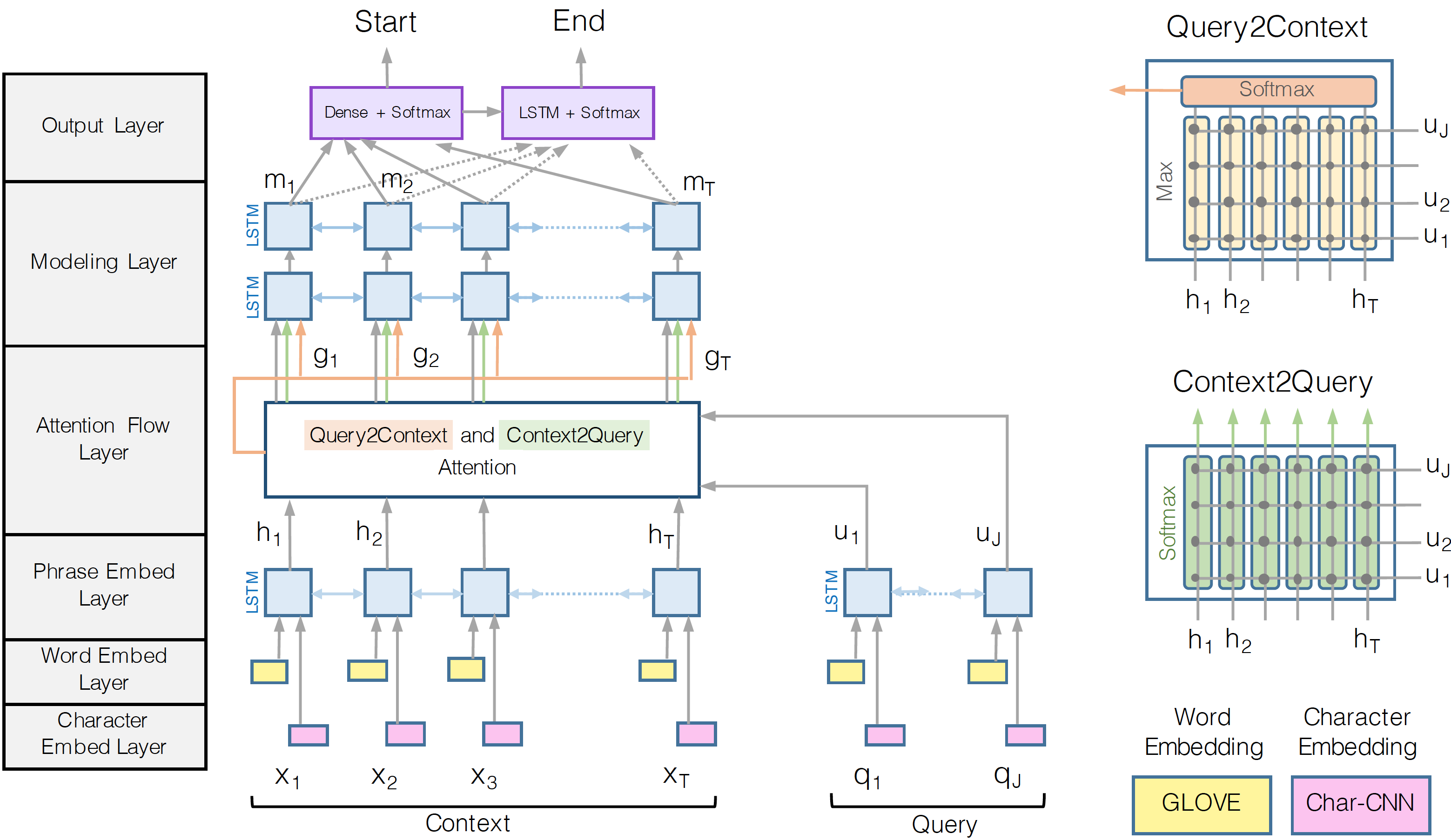
This week we took very big steps towards completing the BiDAF model. In addition to what we have done last week, we implemented and added a highway network in the Phrase embed layer as specified in the paper. Also, and most importantly, we implemented the Query2Context attention part of the attention layer. The Query2Context attention signifies what context words have the closest similarity to the query words, which theoretically should improve the accuracy of our model. We found the model to be more complicated than what the graph implies. However, we still were able to implement almost all of it. We are omitting the char embed layer for now, as we think it’s very complex and have lower priority to other parts of the model. This BiDAF model gave us our best results yet, however, it is not much better than the previous attention or co-attention models. Here are our numbers: Batch size: 512, Learning rate: 0.01, Optimizer: Adam
| Metric | BiDAF |
|---|---|
| Bleu-1 | 0.539 |
| Bleu-2 | 0.519 |
| Bleu-3 | 0.506 |
| Bleu-4 | 0.496 |
| Rouge-L | 0.576 |
For next week: we will try to debug our model to make sure that different layers are working as intended.
Introduced Multiple Passages
We figured with time running short, it was time to start to incorporate multiple passages into the model. In our eyes, there were two main ways of doing this, first, feed all the passages into the model and have some sort of attention mechanism find the relevant passages. The second option would be to calculate a probability of how relevant the passage was, then feed each passage through the model, take the probability distribution of the start and end index over the words, multiple the probabilities by the probability that the passage is relevant, and finally taking an argmax to find the answer.
For this first attempt at the multi-passage model, we decided to go with the first option with advice from Maarten. But instead of having a set of learned attention waits, we took the cosine similarities of the tf-idf vectors mentioned last week, and performed a softmax over them to get probability distribution of which passages are relevant. From there, we apply these weights to the output vectors from the ‘Phrase Embed Layer’ viewed below.
Since this was our first attempt, we stuck with just concatenating the inputs together to make one long string. In future attempts, it may be beneficial to have the LSTM in the ‘Phrase Embed Layer’ read only single passages at a time, so it does not need to learn to embed context from multiple different passages at once.
Running the model for 50 epochs, with an embedding and hidden size of 50, and a learning rate of 0.01, we got the following results:
| Metric | BiDAF-Multi |
|---|---|
| Bleu-1 | 0.101 |
| Bleu-2 | 0.081 |
| Bleu-3 | 0.070 |
| Bleu-4 | 0.062 |
| Rouge-L | 0.291 |
Error Analysis
Now that we have extended the model to work with multiple passages, errors seem to fall into the following categories:
- Wrong passage selected.
- Too many passages selected.
- No answer provided.
In last week’s blog post, we talked about creating a system for determining passage relevance. This system was only able to predict the selected passage about 23.2% of the time, but we hoped that we would still be able to get reasonable answers even when selecting the wrong passage. This does seem to be the case. Even when our model uses the wrong passage, it comes up with reasonable answers. They are often quite different from the reference answer, but they are still reasonable. This is bittersweet, because it means that the model is working, but still has terrible Bleu scores.
Another issue with our model is that it sometimes creates answers that span more than one passage. This problem stems from the fact that we are currently concatenating all of the context passages together and feeding them into the model. There is no mechanism to prevent the model from creating answers that span multiple passages. This issue could explain our low Bleu scores since these are based on precision. It also explains why out Rouge-L scores are much better than our Bleu scores, since Rouge-L is based on a longest common subsequence statistic.
In some cases, our model provides no answer at all. It simply outputs 0, 0 for the start and end indices. Fixing this could be a relatively easy way to boost our model’s performance.
To see a comparison of the BiDAF and BiDAF no-highway models, click here.
How to Improve
Needless to say, these results are pretty disappointing. We fully expected a dip in our performance since we are now sending in much more text into the model, some relevant and some not. The very low numbers can be due to a number of reasons, including a possible bug in our implementation. Looking forward to what to do next to fix the model, our first step was contacting Minjoon Seo, one of the original authors of the BiDAF paper. We hope that we can possibly give us a few pointers on how to improve and maybe even where a bug may be present in the code.
Alternate approaches include the argmax model that we mentioned in the previous section, and also sorting the passages based on their relevance scores. This way the answer should lie closer to the beginning of the concatenated text, although, this should not be necessary for the model to succeed. One other possible change that would be easy would be apply the passage relevance weights elsewhere in the model. Without much prior knowledge of attention mechanisms, this would take some playing with.
Demo Work
An ideal demo for this project would allow someone to get a succinct answer to an arbitrary question much like they would with a search engine. Unfortunately, there are quite a few obstacles to building such a system. In the training set, each question comes with a multiple context passages that are extracted from web pages using Bing. The MS MARCO paper does not provide details on exactly how passages were extracted. It states that “the passages were selected through a separate IR (information retrieval) based machine learned system.” The task of extracting relevant context from a webpage would be a substantial research project on its own. Since we don’t have the time to do this, there are a couple alternatives.
We could simply allow the user to enter context themselves. This may work, but it would be tedious for a demo since each query in the training set has about ten associated context passages. Our model may also not generalize well to user provided context since it was trained on context from web pages. Another problem with this approach is that we currently have separate models for each question type. We would either have to make the user select a question type, or build a simple classifier to predict the question type.
Another option would be to restrict queries to the public testing dataset from MS MARCO. This would be simple to implement but not nearly as interesting as allowing the user to enter arbitrary queries.
Currently, we can enter an arbitrary query and context passage and extract an anwer from the model. For our demo, I think that providing example questions from the test set but also allowing free-form input would provide the best experience.