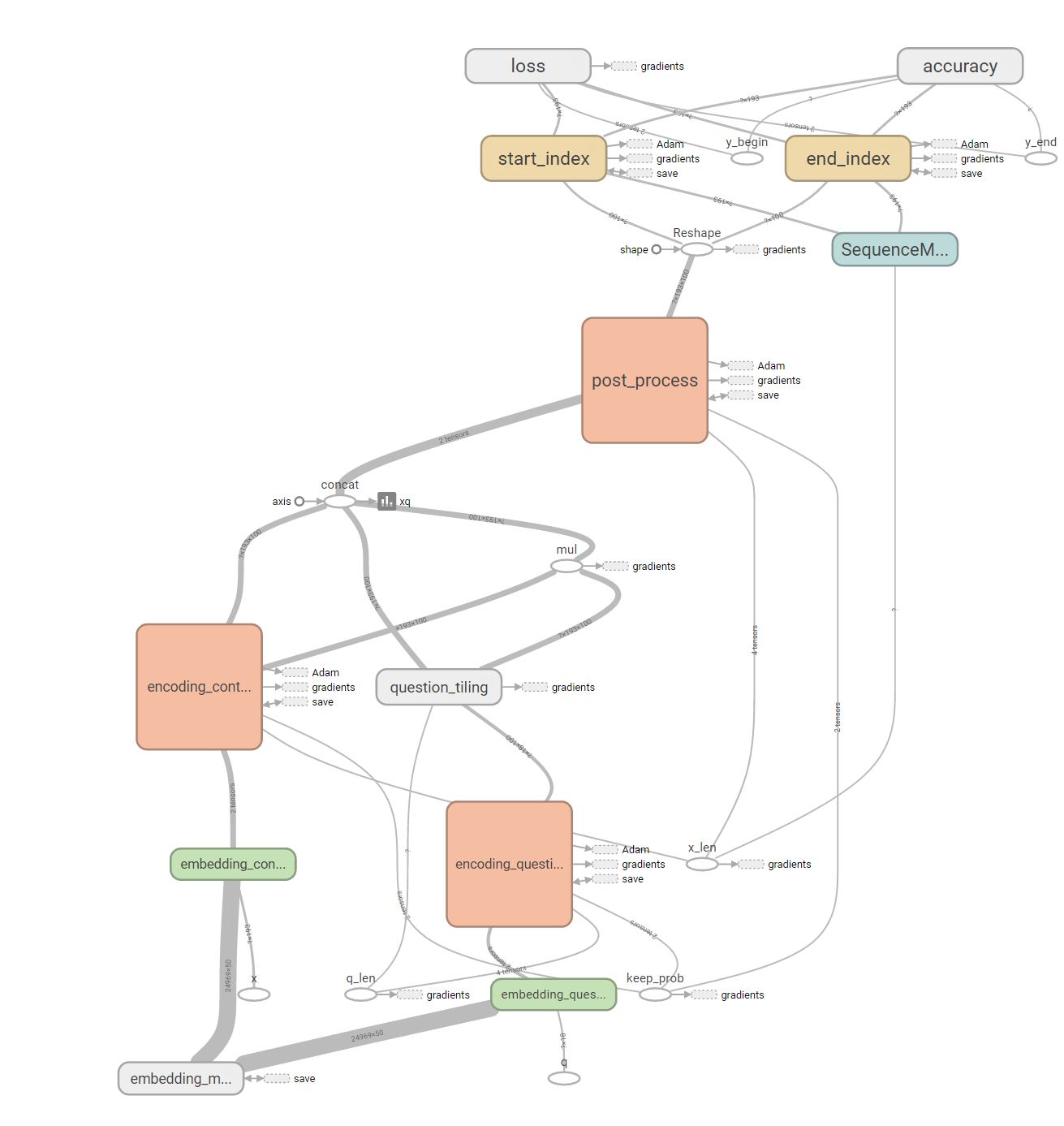
Multiple Baseline Models' Performance and Error Analysis
Baseline Model (Old)
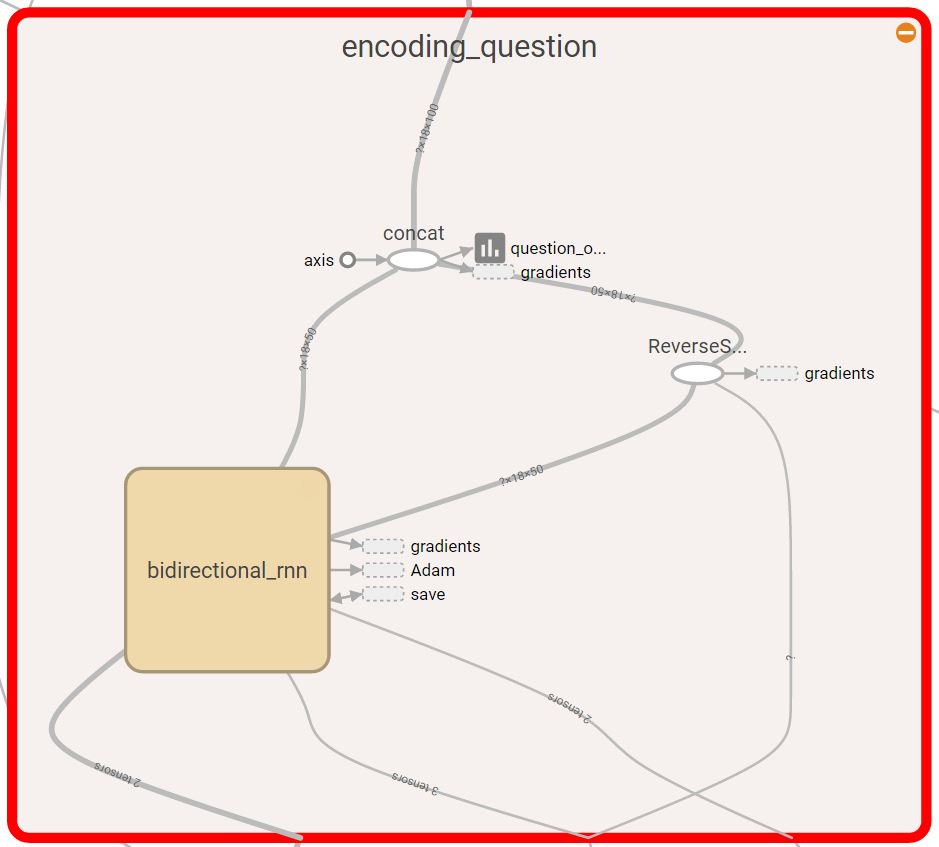
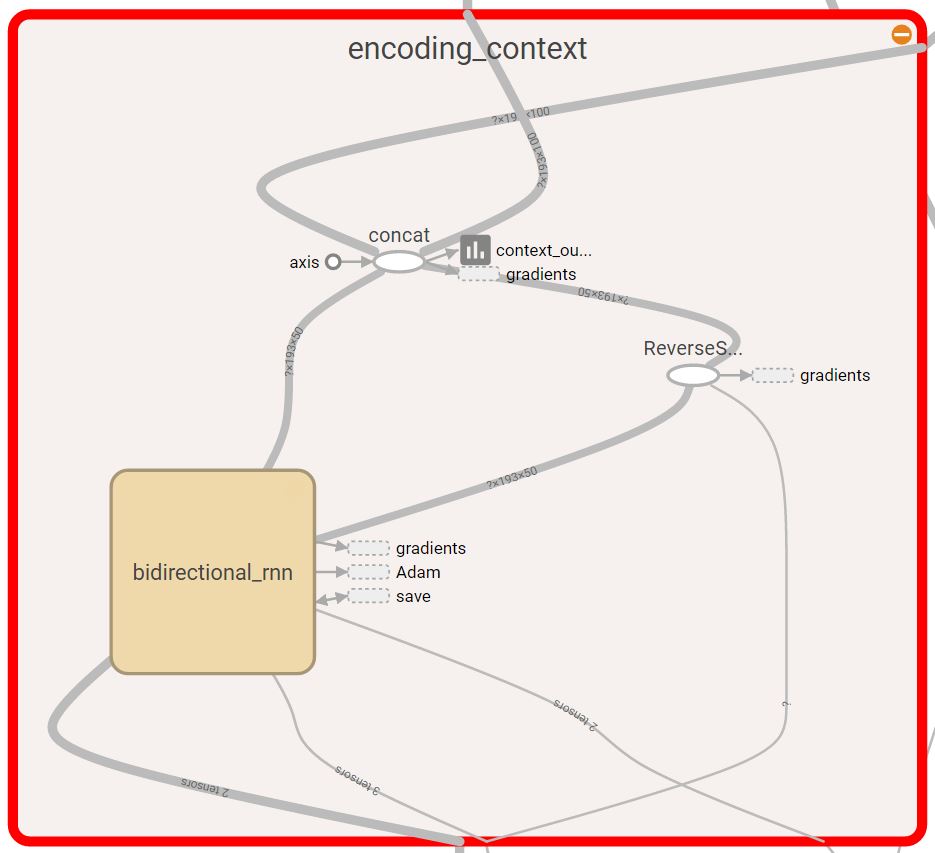
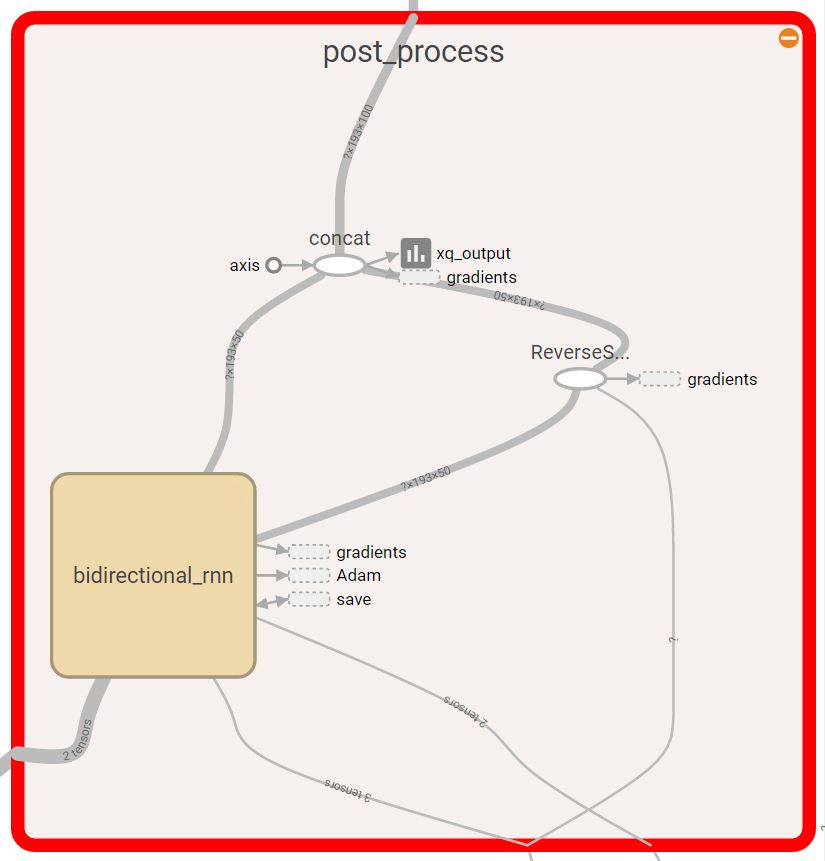
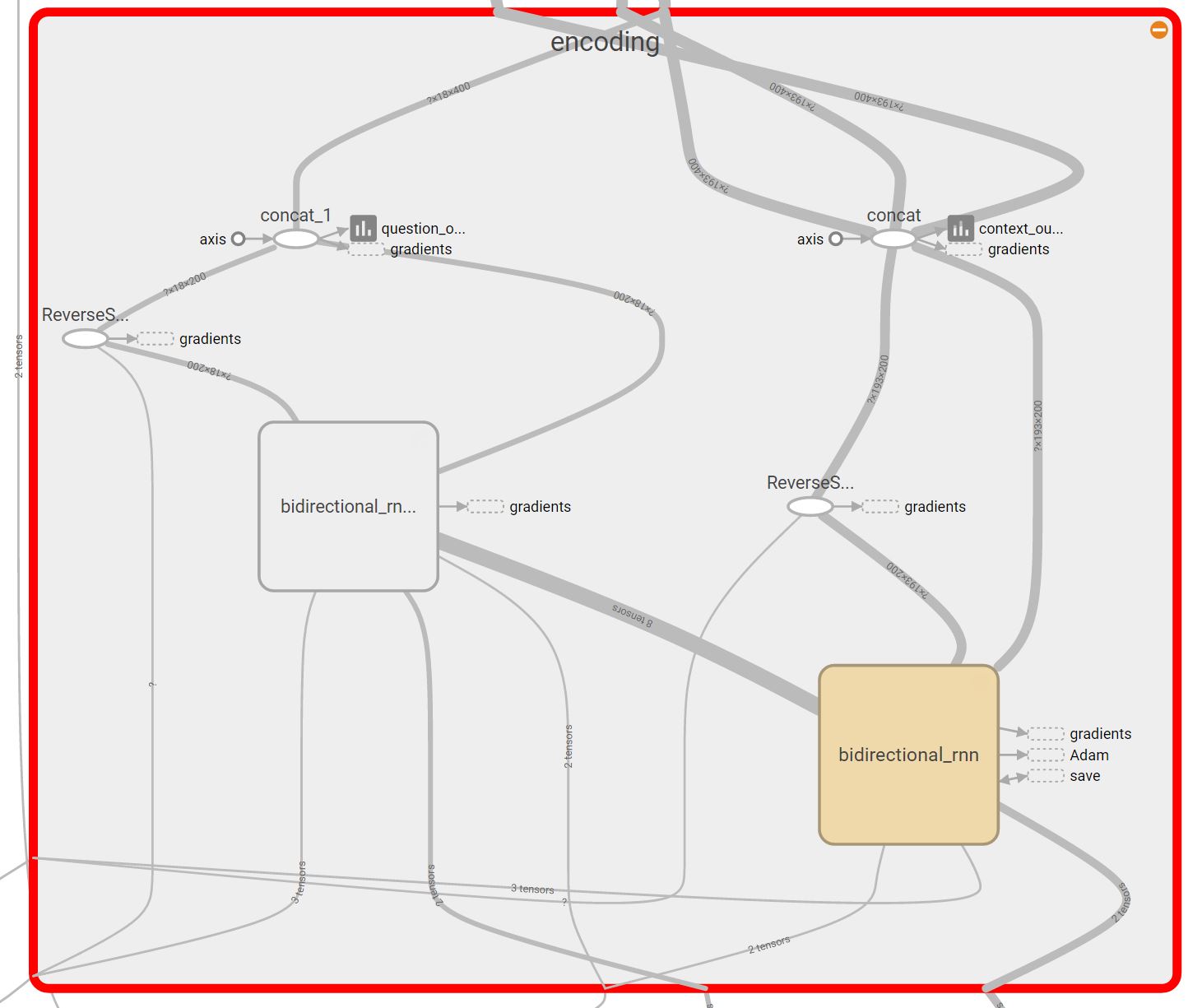
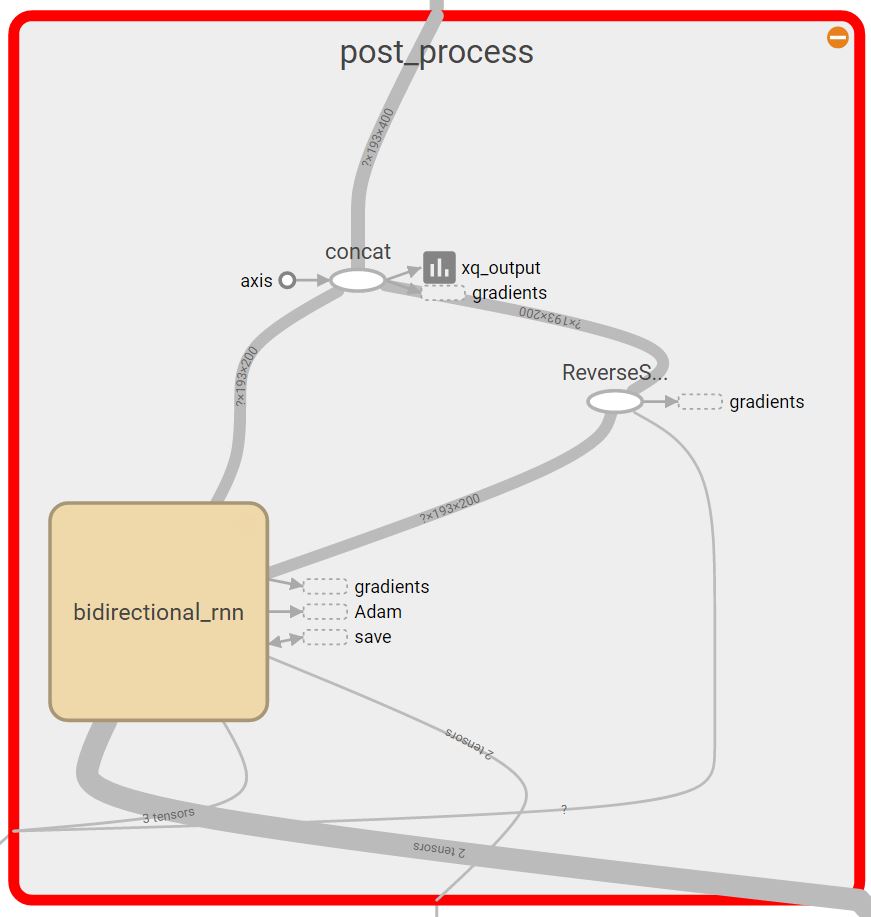
For our baseline model, we started with a very basic design. The model has two bi-directional dynamic GRU RNN’s. The first RNN takes a matrix of the word embeddings of the question, and the second RNN takes the word embeddings of the context. The output of each RNN is the concatenation of the backward and forward outputs of that RNN. The output of the question RNN is a matrix representing a vector for each word in the question. The question representation we later consider is an average of the different word vectors outputted from the question RNN. The question representation and the output of the context RNN are concatenated and inserted in a third bi-directional dynamic GRU RNN. Then, we have a dense output layer that takes the output of the third RNN. From the output layer we get the logits for the starting and ending indices of the answer, from which we take the arg max. All three RNN’s have a dropout as a regularization technique to reduce overfitting during training.
Overview of the model from Tensorboard
The expansion of the question encoding block
The expansion of the context encoding block
The expansion of the post process block
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Baseline Attention Model (New)
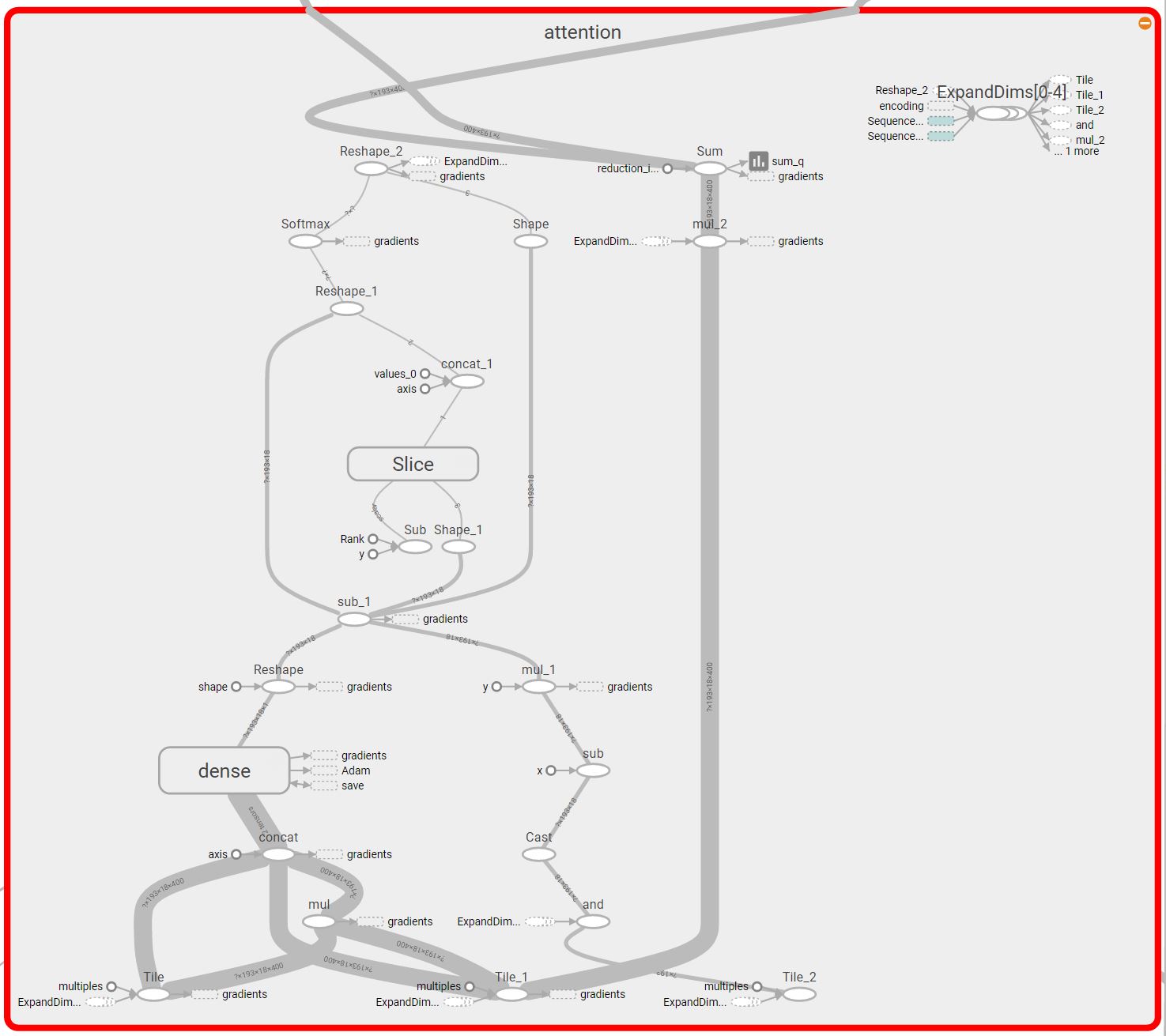
The attention model is very similar to the old baseline model. The only difference is in defining the question representation that we use in the third RNN. Before, we used to average the difference word vectors we’re getting from the question RNN, we do a weighted average with trained weights.
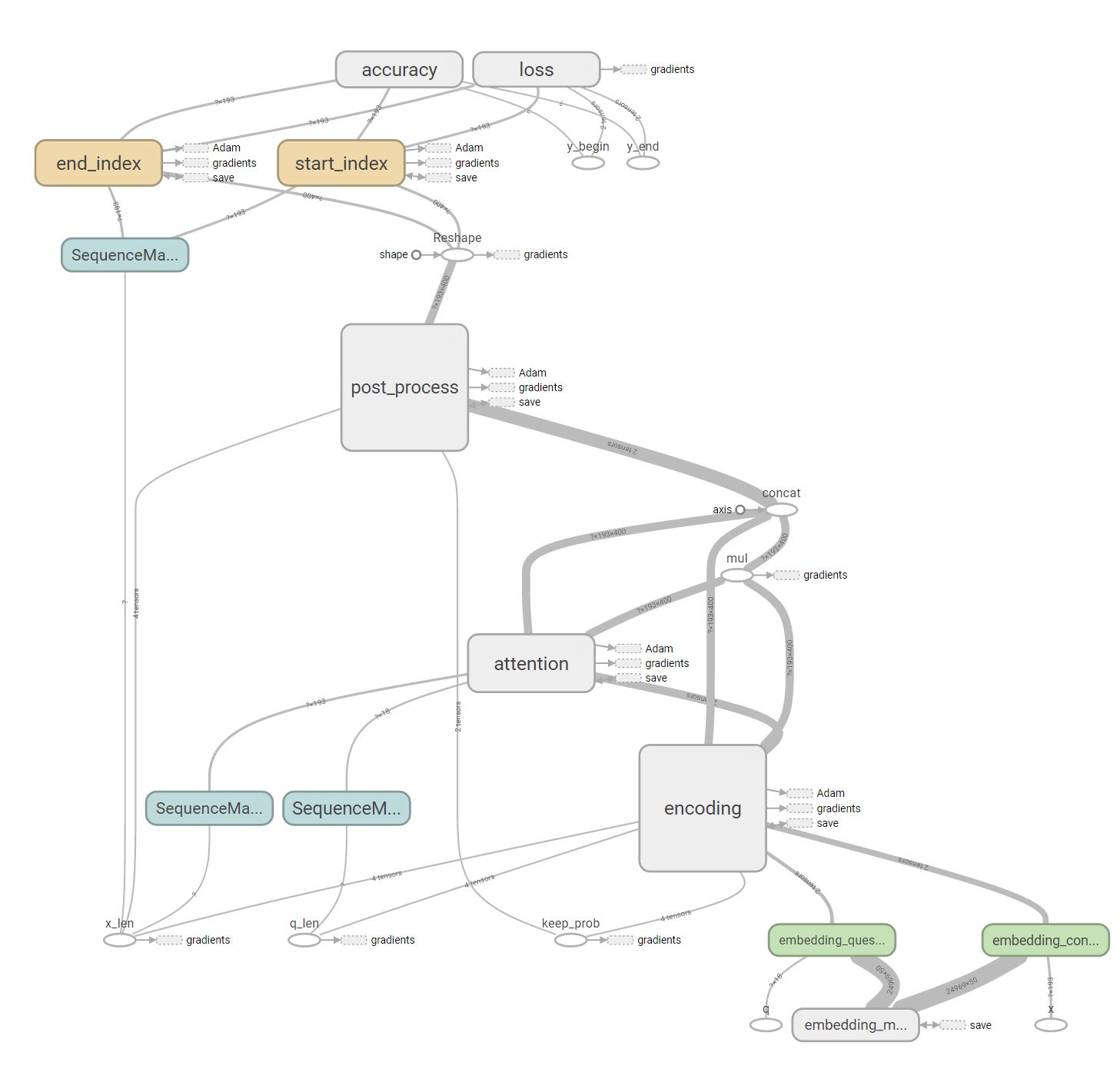
Overview of the model from Tensorboard
The expansion of the encoding block
The expansion of the attention block
The expansion of the post process block
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Initial Hyperparameter Tuning
These baseline models have multiple hyperparameters to tune, all of which can be controlled through the command line interface. So far, our list includes:
- Keep Probability - Used to configure all dropout layers within the model
- Embeddings Size Attention - Can be 50, 100, 200, or 300. Chooses which pretrained embeddings to load
- Learning Rate - Used as the hyperparameter within the model optimizer
- Hidden Size - Dimensions of hidden layers within RNN cells for encoding and decoding data
- Epochs - Number of passes over the training data
- Batch Size - Number of training samples to feed into the system at once, greatly effects runtime on GPU
In addition to these hyperparameters, the command line interface can also configure which model to use as well as which question type. With all this, we decided to run a couple of experiments in order to get a rough idea of what makes good default values for these values. We captured the results in Tensorboard, which are displayed below. As a note, the overall loss is the sum of the loss for the starting and ending index losses. Those individual losses are measuring exact matches of those indices.
For these experiments, we trained and tested on the location question type, for 50 epochs, with an embedding size of 50. We varied the batch size based on the model, since using too large of a batch size caused OOM (Out of Memory) errors. Therefore we will analyze the effect of different keep probabilities, learning rates, and hidden sizes.
(Sorry for the lack of a color key, was cut off by the browser but can follow which line is which with the values)
Keep Probability
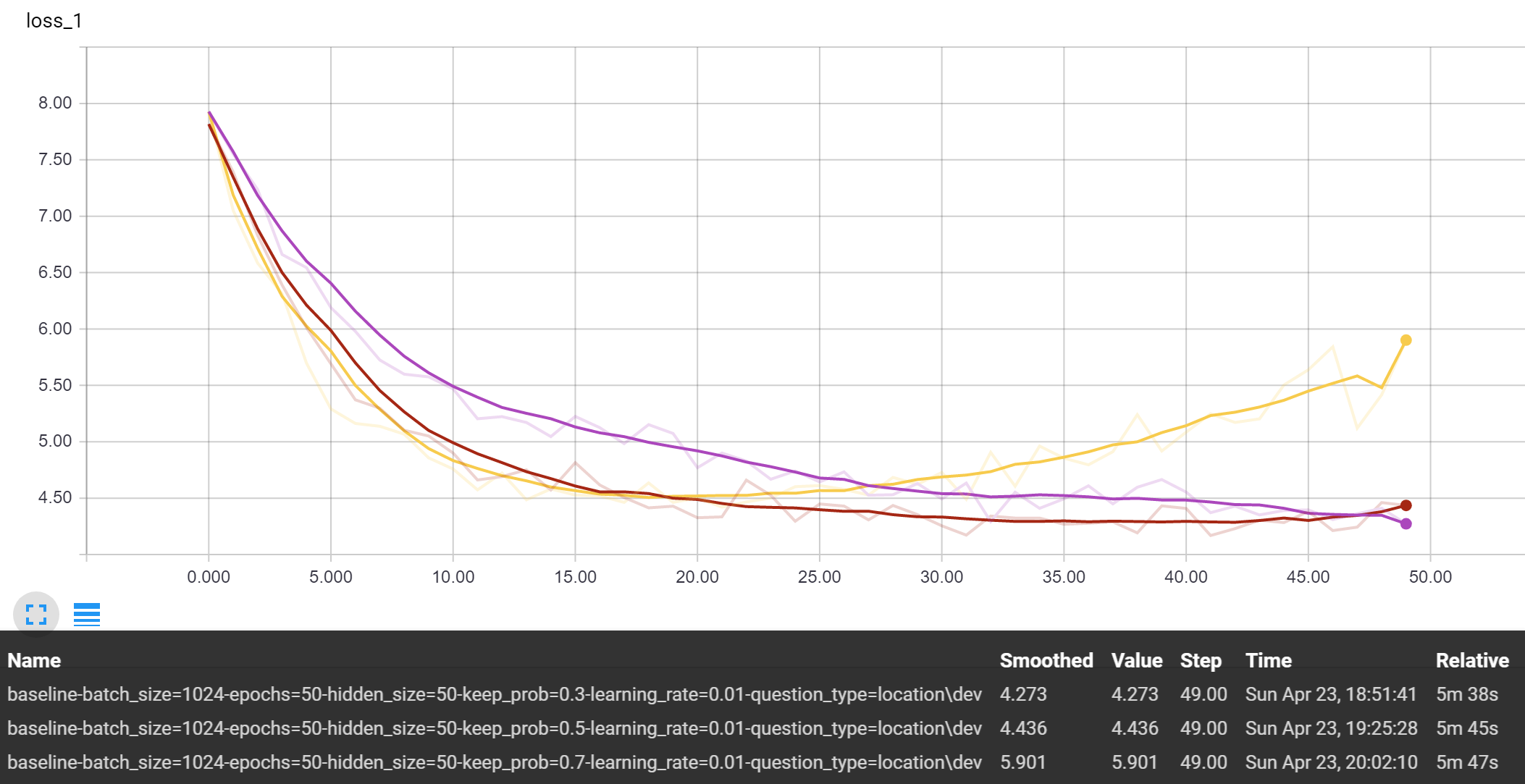
Holding the hidden size at 50 and learning rate at 0.01, we can observe the performance of the baseline and baseline attention model model:
Baseline
Baseline Attention
Clearly, the keep probability of 0.7 was prone to overfitting and performed the worst on both models after 50 epochs. But within these first 50 epochs, the 0.3 and 0.5 keep probabilities performed comparably. If we extend the training longer, we hypothesis that the 0.3 value will eventually work better.
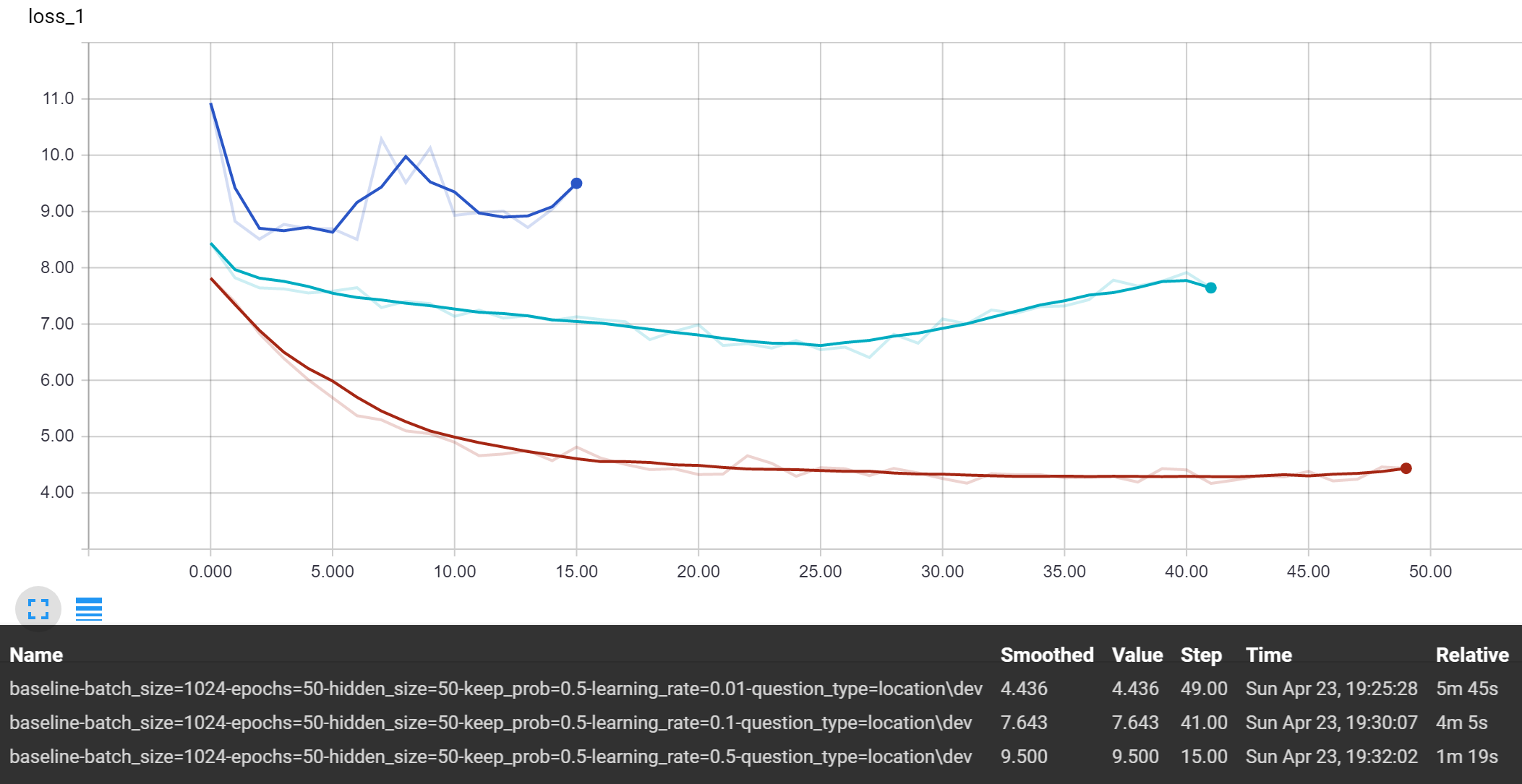
Learning Rate
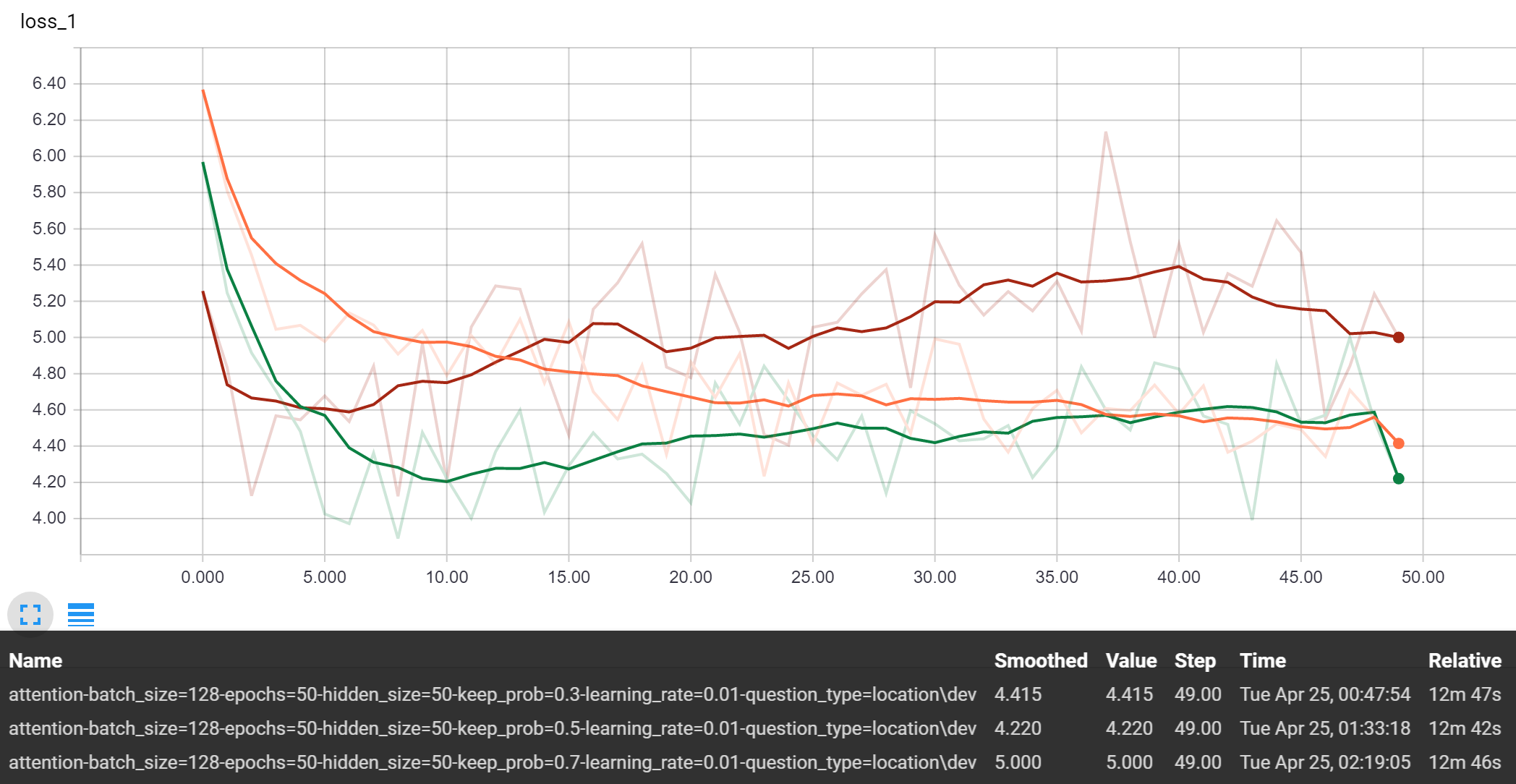
Holding the hidden size at 50 and keep probability at 0.5, we can observe the performance of the baseline and baseline attention model model:
Baseline
Baseline Attention
Just by viewing the performance of the models above, it is quite obvious that the 0.01 learning rate performed the best. In fact, the 0.5 rate would not even work with the attention model since it ran into Tensorflow issues with NaN values. Moving forward, we will choose to use 0.01 as a default rate and do further tuning to the hyperparameter once we have a more advanced model.
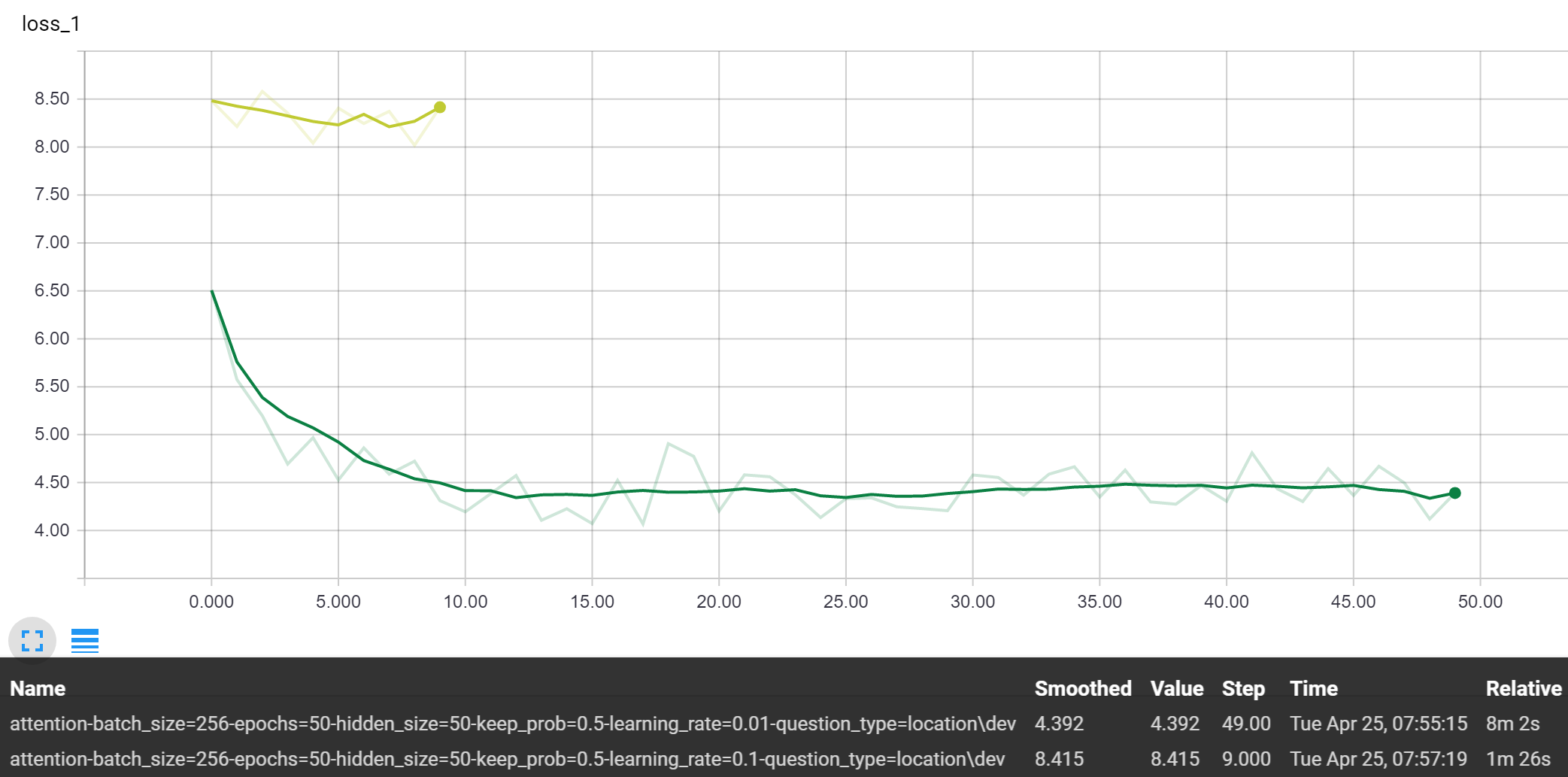
Hidden Size
Holding the learning rate at 0.01 and keep probability at 0.5, we can observe the performance of the baseline and baseline attention model model:
Baseline
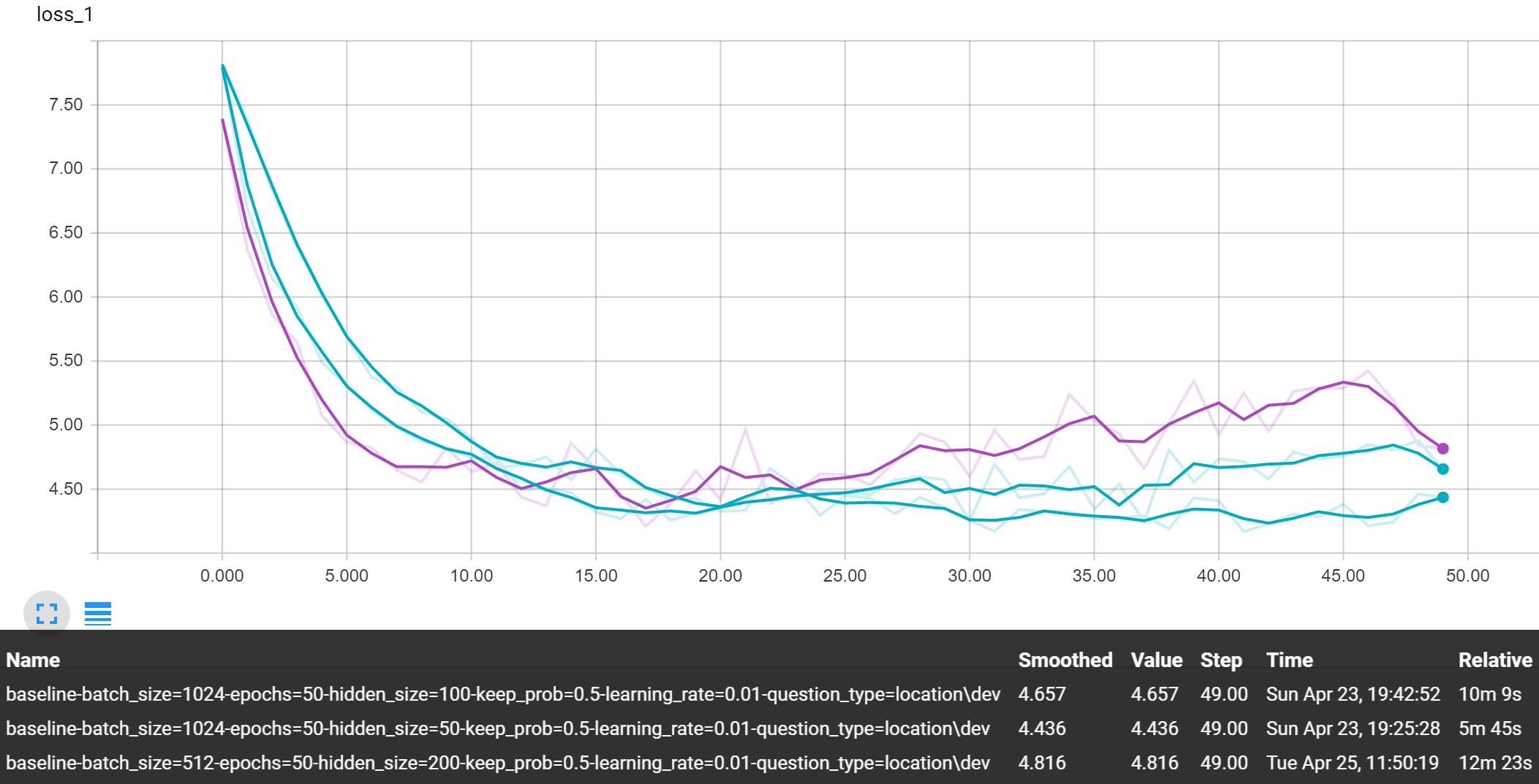
Baseline Attention
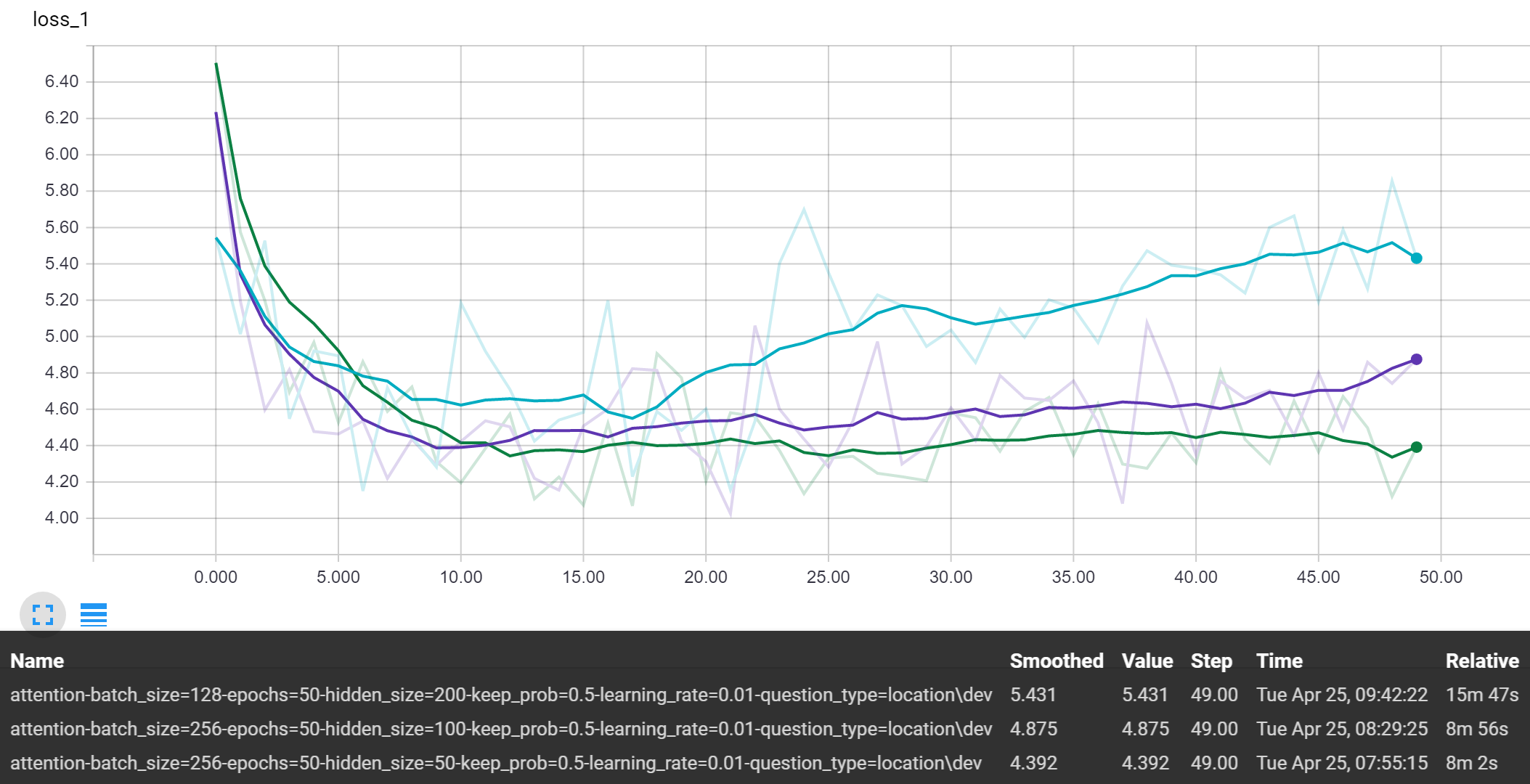
The differences in performance for the varying hidden sizes are much smaller than with the other hyperparameters we tested. But yet, we still view the trend that the smaller this value is, the better with these baseline models. Using the value of 50, for now, was a nice balance between having the representative power to learn patterns, while not being too large and overfitting the training data.
Performance of Attention vs. Non-Attention Model
| Metric | Baseline | Attention |
|---|---|---|
| Bleu-1 | 0.46628592483410713 | 0.5262784090907845 |
| Bleu-2 | 0.4465765025306 | 0.504594817194436 |
| Bleu-3 | 0.43214005711862286 | 0.4901243640485685 |
| Bleu-4 | 0.42061838668735313 | 0.4789423866936625 |
| Rouge-L | 0.537926438973 | 0.517672487849 |
The attention model achieves significantly better Bleu scores than the non-attention model. I suspect that its Rouge-L performance is slightly worse because it tends to produce shorter answers than the baseline. Since Rouge-L is based on the longest common substring, this results in a worse score.
For our initial models, we have only been considering passages that contain the answer to the query. This means that we have to find the answer in one passage instead of ten. Once we start using all of the passages, the attention mechanism will be much more important.
Error Analysis
Initially, our baseline attention model performs very similarly to our baseline model, as a results, for our error analysis we choose to just focus on the baseline model.
General Observations
When searching for patterns in the errors made by our baseline model, we came across some noteworthy point:
- Already, the model is selected what seem to be reasonably answers. By this we mean it is not just selecting random words, it is selecting spans of words that could be an answer. Although the semantics can be off, we are happy to see the word span the model is selecting is a reasonable answer.
- The training data seems to be somewhat inconsistent. There are many examples in which the training data includes supplementary details around the main answer, and many examples where the answer is just a word or two. Each case provides correct answers, but with different styles. The main lesson to learn from this is that we need to make sure to not overfit the training data, the evaluation is looking for the content of the answer, not the exact match on the indices.
-
There are some few patterns in the errors made by our baseline model. We believe these mistakes are largely due to inconsistency in the training data as mentioned in the previous point. The pattern we found is that the model often times answers correctly but give too much or too little details compared to the reference answer. Looking at these mistakes we can put them in a few different categories:
1) Include preposition? Since our model is trained on location questions, many answers may start with some preposition. Sometimes the model includes a preposition in beginning of the answer when it shouldn’t, and vice versa. Here are some examples:
Passage: lactose intolerance is the inability to digest a sugar called lactose that ‘s found mainly in milk and dairy products . normally , the small intestine produces an enzyme called lactase , which breaks down lactose into two simple sugars , glucose and galactose , that can be absorbed into the bloodstream .
Question: where does lactase come from?
Reference Answer: milk and dairy products .
Our Answer: in milk and dairy products .Passage: animals . climate . return to savanna . the african savanna biome is a tropical grassland in africa between latitude 15° north and 30 degrees s and longitude 15 degrees w and 40° west .
Question: where are the savannas in africa?
Reference Answer: in africa between latitude 15° north and 30 degrees s and longitude 15 degrees w and 40° west .
Our Answer: africa between latitude 15° north and 30 degrees s and longitude 15 degrees w and 40° west .2) Full or brief answer? Some times it gives a full answer when the reference requires a brief answer, some times the other way around:
Passage: welcome to zama and cozara , please choose which restaurant and menu you ‘d like to view : zama is located at 128 south 19th street in rittenhouse row . zama brings the rich culinary traditions of japan to center city . the restaurant offers more than 30 a la carte sashimi , as well as a wide variety of maki rolls and vegetable offerings .
Question: where was zama located?
Reference Answer: 128 south 19th street in rittenhouse row
Our Answer: zama is located at 128 south 19th street in rittenhouse row3) Include punctuation? There is an inconsistency in the training dataset on whether to include the punctuations (usually the full stop at the end) or not. This causes an inconsistency in our model as well:
Passage: the given vietnam location map shows that vietnam is located in the south-east asia . vietnam map also shows that vietnam is the easternmost country on the indo-china peninsula . map of vietnam illustrates that vietnam shares its international boundaries with china in the north , laos in the north-west , thailand in the west , and cambodia in the south-west . besides , south china sea lies in the east
Question: where is vietnam located?
Reference Answer: south-east asia
Our Answer: south-east asia .4) Describe the location? Sometimes the model decides to be generous and gives a full description of the place whereas the name would suffice. Some other times the opposite happens. This happens with the training set as well. Here are some examples:
Passage: geographic range . nautilus pompilius is found in the indo-pacific area . they primarily live near the bottom , in waters up to 500 meters deep , but rise closer to the surface throughout the night . ( morton 1979 ) . 1 biogeographic regions . 2 pacific ocean . 3 native .
Question: where do the nautilus pompilius live?
Reference Answer: indo-pacific area .
Our Answer: indo-pacific area . they primarily live near the bottom , in waters up to 500 meters deep , but rise closer to the surface throughout the night . ( morton 1979 ) . 1 biogeographic regions . 2 pacific ocean .Passage: continents are very large landmasses found on earth . the earth has seven such continents . they are ( from largest in size to the smallest ) : asia , africa , north america , south america , antarctica , europe and australia . asia-asia is the world’s largest and most populous continent on earth . it covers 30 % of the earth’s land area . asia hosts about 60 % of the world’s current human population .
Question: what are the continents around the world?
Reference Answer: asia , africa , north america , south america , antarctica , europe and australia . asia-asia is the world’s largest and most populous continent on earth .
Our Answer: asia , africa , north america , south america , antarctica , europe and australia .
These are the most obvious patterns we found.
Finally, just for fun, here is our model trying to be a smart***:
Passage: considerations . the involuntary eye movements of nystagmus are caused by abnormal function in the areas of the brain that control eye movements . the part of the inner ear that senses movement and position ( the labyrinth ) helps
Question: where in the brain are eye movements controlled
Reference Answer: abnormal function in the areas of the brain
Our Answer: in the areas of the brain that control eye movements .